菱洋エレクトロ株式会社は、生成AIの性能を前世代比で最大3倍※1向上させる新GPU「NVIDIA RTX™ A1000」の取り扱いを開始いたします。
生成AIの普及が続く中で、高速なパフォーマンスを損なうことなく、設置面積を最小限に抑えられるコンパクトなワークステーションへの需要が増えています。
2,304個のCUDA®コア、18個のRTコア、72個のTensorコア、8GBのGDDR6メモリ、そして最大4台の5Kディスプレイを駆動する機能を備えた本製品はグラフィックスに携わるプロフェッショナルのパフォーマンスを向上させるため、菱洋エレクトロでは評価用の貸出機器を用意し、デスクトップ環境でのご利用を想定されている方へ、「スモールファクターのGPUでワークステーションの省スペースを実現したい」といったニーズや課題をお持ちのお客様へご提案・ご提供を予定しております。
 NVIDIA RTX™ A1000
NVIDIA RTX™ A1000
【製品の特長】※2
1.最大2.7倍のスループットを実現する2,304個のCUDA®コア
NVIDIA AmpereアーキテクチャーベースのCUDA®コアは、前世代(T1000)と比較して単精度浮動小数点のスループットを最大 2.7 倍※1にし、2D グラフィックス、3D モデルなどのレンダリングや、基本的な写真や動画編集、データ分析などアプリケーションのパフォーマンスを大幅に向上させます。
本製品は2つのFP32プライマリデータパスを有効にし、ピーク時のFP32動作を2倍※1にします。
2. 初の小さなフォームファクターに搭載された第2世代RTコア
第 2 世代のレイトレーシングエンジンを組み込んだ NVIDIA Ampere アーキテクチャーベースのGPUは、驚異的なレイトレーシングパフォーマンスを提供します。 NVIDIAは初めて、ロープロファイルのシングルスロットフォームファクターGPUにRTコアを導入します。本製品があれば、物理的に正確な影、反射、屈折を備えた複雑なモデルをレンダリングすることができます。
さらに、前世代と比較しレンダリングパフォーマンスが最大 3 倍※1高速になりました。このテクノロジーは、レイトレースモーションブラーのレンダリングを高速化し、より高い視覚的精度でより高速な結果を実現します。本製品のシステムは、NVIDIA OptiX™、Microsoft DXR、Vulkanレイトレーシングなどの API を活用するアプリケーションと連携して、真にインタラクティブな設計を強化し、より効率的な生産性を提供します。
3. 最大 3倍の生成 AI パフォーマンスを実現する第3世代Tensorコア
NVIDIA Ampere GPU アーキテクチャーの第3世代Tensorコアは、前世代と比較し生成 AI のパフォーマンスが最大 3 倍以上※1高速になりました。第3世代Tensorコアは、TF32およびBFloat16データフォーマットのサポートにより、パフォーマンスと精度を向上させるため幅広いAIモデルの対応が可能になります。
※1 NVIDIAによるRTX A1000 および NVIDIA T1000 8GB GPU と Intel Core i9-12900K を使用したパフォーマンステストによるもの
※2 本リリースに記載されている情報は発表日現在のものです。時間の経過あるいは後発的なさまざまな事象によって内容に変更が生じる可能性があります。あらかじめご了承ください。
【製品仕様】
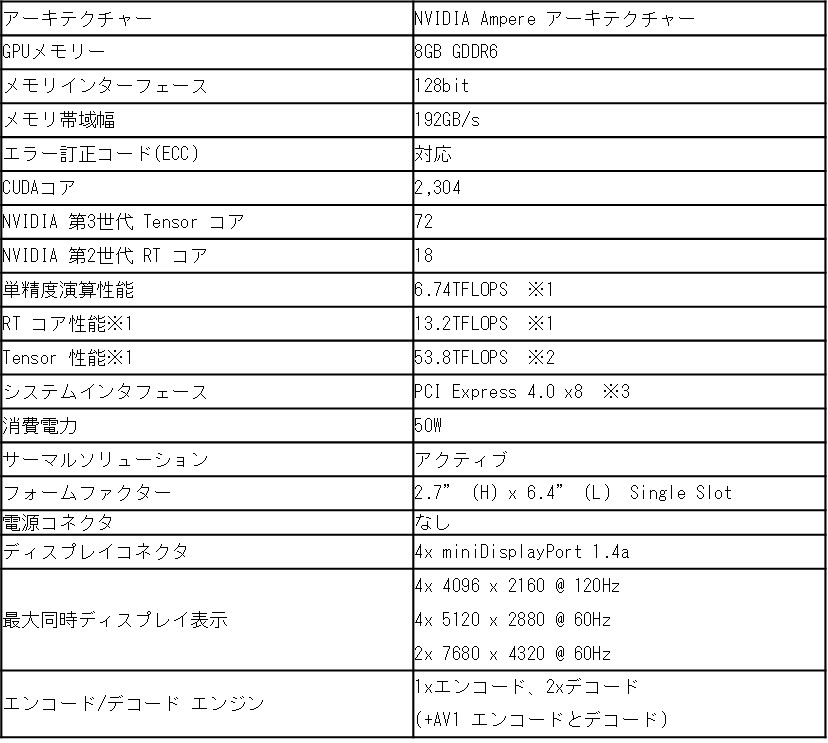
※1 ピークレートはGPUブーストクロックに基づいています。
※2 効果的なFP8テラフロップス(TFLOPS)はスパース性を使用しています。
※3 本製品は、フルレングスのPCIe Gen 4 x8インターフェースを利用しています。
ご依頼・ご相談など、お問い合わせは、
下記フォームからお願いいたします。